Defeating Deepfaked Video Calls by Monitoring Electrical Fluctuations
2022 has seen the emergence of 'live' deepfakes in videoconferencing as an acknowledged security threat. In June, the FBI issued a warning to businesses about the increasing use of deepfake technologies to apply for remote work positions; in July, also in the United States, the Better Business Bureau (BBB) warned against the use of deepfakes as an enabler for a new and unsettling strain of fraudulent and criminal phishing and social engineering attacks.
The first known major deepfake fraud was revealed in 2021, with the disclosure of details of an audio-based deepfake call that enabled attackers to force a banking official to transfer $35 million to a previously unknown account.
The mere existence of 'live' video and audio deepfakes is proving to be a kind of 'terrorist attack' on reality, throwing the veracity of sound and video content into doubt, even in controversial events where deepfakes may not have been used.
Intruder Alert
Over the last 18 months, the security research community has stepped up its efforts to create more effective deepfake detection systems, and are increasingly concentrating on the new phenomenon of live deepfakes.
One such initiative, just released, comes from the U.S. Air Force Research Laboratory in Rome, USA, in collaboration with researchers from Binghamton University in New York.
The new method, dubbed DeFakePro, uses the unique Electrical Network Frequency (ENF) that's intrinsically embedded into any audio or video recording as an 'unforgeable' signal to distinguish real from faked video and audio signals in a live videoconferencing environment.
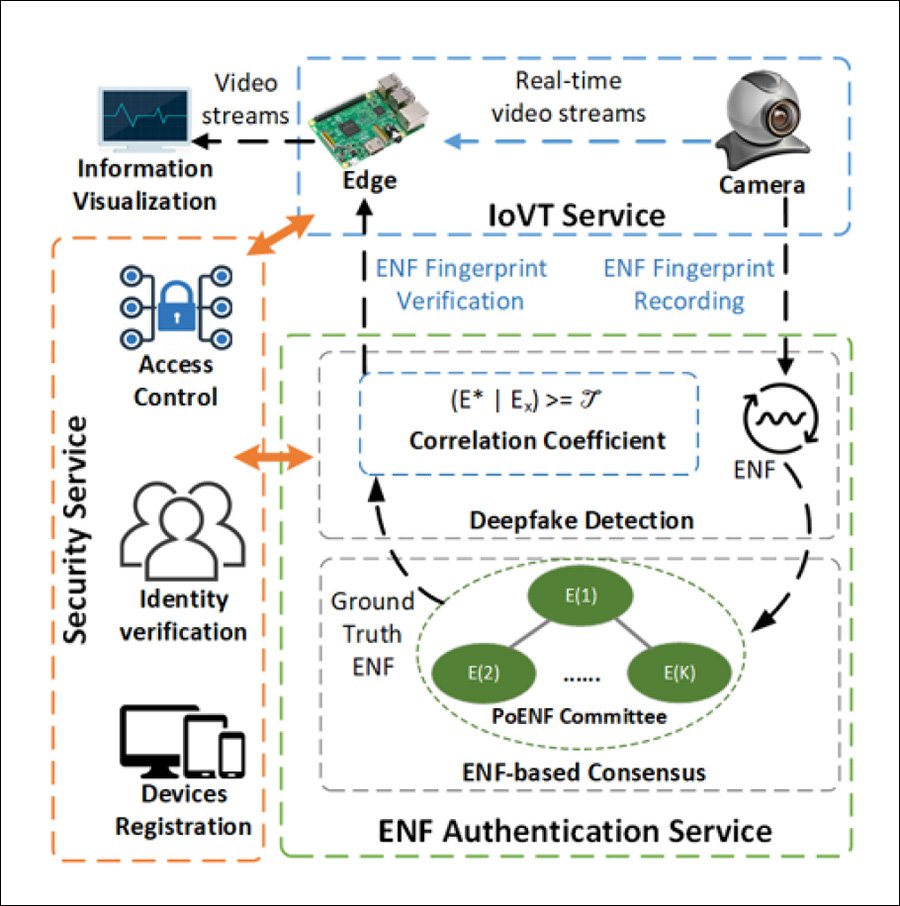
ENF is a frequency in power distribution networks that occurs because of fluctuations in load control, and varies across regions and environments. So long as the participant is not situated outdoors, ENF becomes reliably embedded in multimedia recording, casting a unique signature across the entirety of the content – a signature that will become distorted if any of that content is 'disturbed' by deepfake intervention.
Though ENF-based authentication systems have been tried before, across a range of potential scenarios (rather than just deepfake detection), the prior use of centralized (non-blockchain) consensus systems gave them a single point of failure for attackers to target. The decentralized system proposed by the authors removes this weakness.
ENF - Energy Spikes as a Signature
In audio content, the ENF signature comes from electromagnetic induction, for plugged-in equipment, or background hum, for battery-powered devices.
In video content, ENF is embedded from illumination fluctuations emitted by light sources powered by the electrical grid (including monitor brightness fluctuations – another active area of investigation in live deepfake video detection).
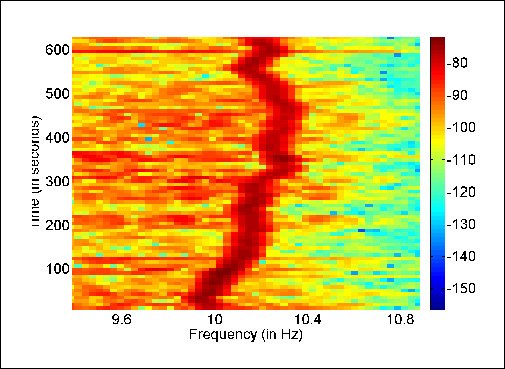
A 120GHz illumination fluctuation in a situation where the average frequency is 60Hz, can be registered from the output of webcams or other capture devices that are participating in the videoconference. The most common sensor in such an environment is a Complementary Metal Oxide Semiconductor (CMOS), where frames are captured with a rolling shutter mechanism, which increases the number of available ENF samples captured (compared to the less common CCD sensor).
In DeFakePro, the ENF of content from each participant is registered into an automated common consensus, through the kind of decentralized authentication mechanism commonly deployed in popular blockchain-based technologies. However, access to the system's consensus mechanism, titled PoENF (Proof-of-ENF), is restricted to a limited and local peer group among the participants.
DeFakePro Vs. DeepFaceLive and Descript
The researchers tested the system in a trial live videoconference environment in which the live deepfake streaming software DeepFaceLive was used to simulate the video presence of 'unreal' participants. The audio facets of the 'unreal' participants were created with the Descript text-to-speech platform, which is capable of using pre-trained vocal models to synthesise speech on-the-fly.
The test environment was set up in Python, with Raspberry Pi-4 (RPi) units acting as constraints to cap the computation power requirements of the system (which needs to operate in real time, with minimal offline computing), and also on a Dell OptiPlex-7010 desktop.
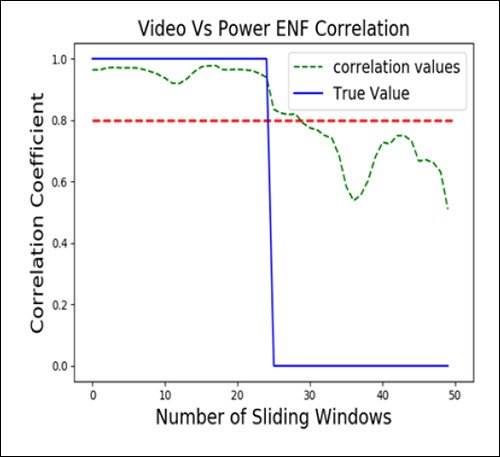
The challenge in a live streaming environment is to collect enough buffered material from the participants' stream to be able to evaluate ENF characteristics, with the problem exacerbated as the number of participants rises. Thus, the researchers tested the accuracy and reliability of DeFakePro in situations where the number of participants varied, and where the 'windows' of available frame buffers also varied in size.
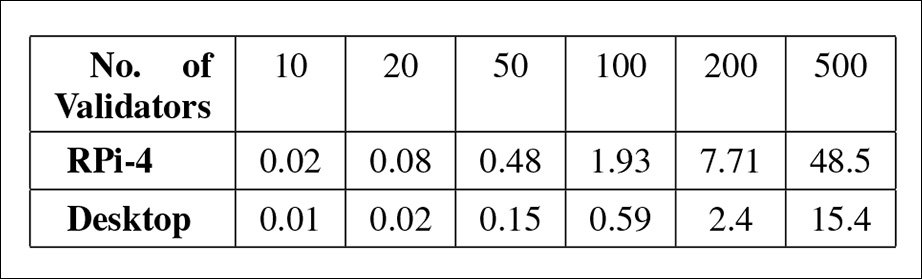
In the above image, we can see that latency increases as the number of participants ('validators') grows, since each of them has to register and participate in the consensus mechanism. At <10 participants, the system operates, in effect, in real time. Even at higher latencies, it can identify fake content in an actionable time-frame. The very worst score, where the Raspberry Pi must contend with 500 participants (an improbable scenario), still delivers an effective identification of fake content in less than a minute.
In a time-critical situation such as a videoconference, it's important to evaluate quickly, and, since the variables are relatively limited, the researchers used Area Under the Curve (AUC), which provides efficient detection.
In the trials, DeFakePro was able to clearly distinguish between real and Descript's deepfaked audio in a range of possible operating environments:
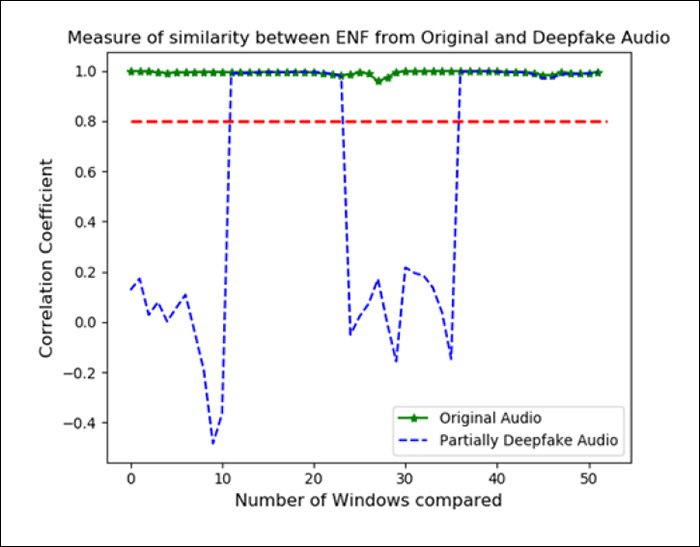
A similar result was obtained for the DeepFaceLive output featured in the tests:
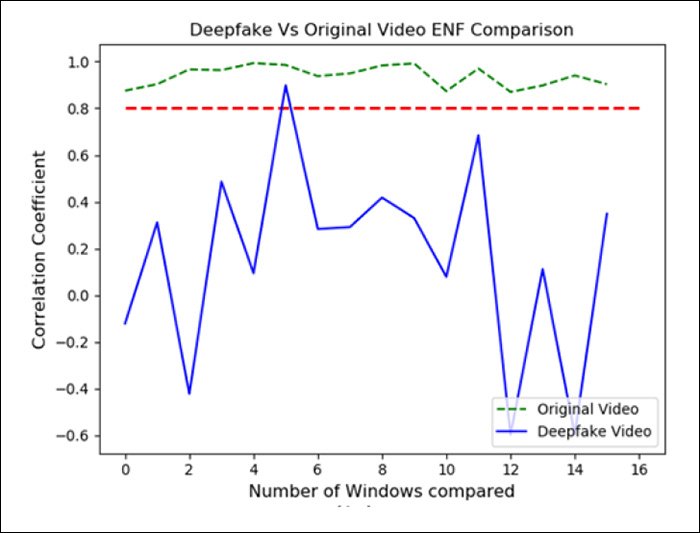
Autoencoder deepfake models do not merely 'paint over' the face of the real participant with a superimposed identity, but are also required to modify the background – for instance, in cases where the profile or outer lineaments of the fake identity are less protuberant than the person being 'overwritten'.
This kind of 'underhang' means that the algorithm must recreate any sections of background that are revealed by the superimposed identity. Therefore additional spectral inconsistencies can also be detected in the background material of the deepfake content stream.
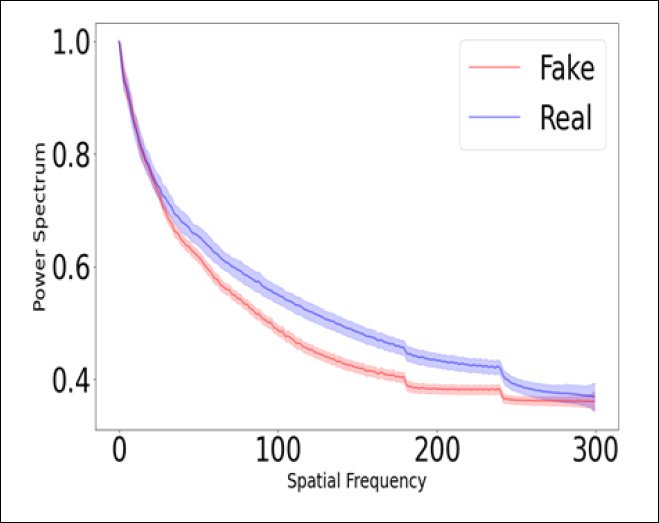
The spatial frequency inconsistencies that DeFakePro is able to home in on are a direct result of the practical limitations of deepfakes, in terms of their ability to produce high-resolution output. A videoconferencing situation is likely to mean that the deepfaked facial content occupies a minimum of 50% of the screen area, at possible resolutions of up to 4K.
This is far in excess of what autoencoder systems such as DeepFaceLive can effectively resolve at the current state of the art, requiring that the faked content be upsampled, which currently guarantees a spectral mismatch.
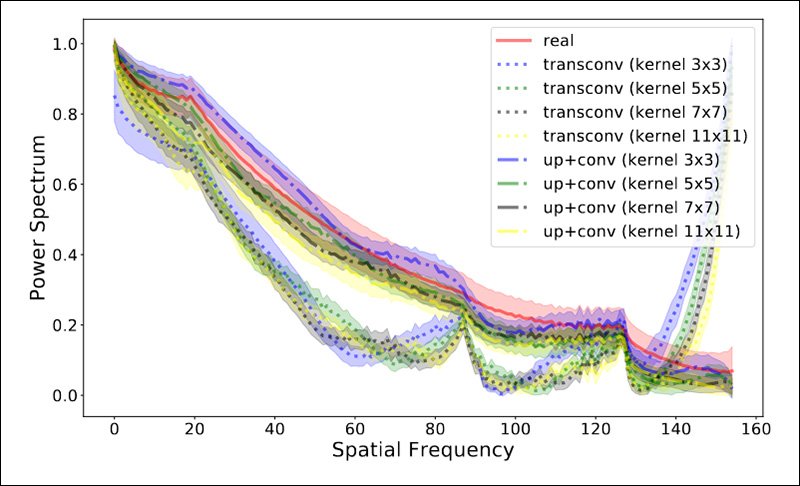
Currently, potential DeepFaceLive video impersonations are operating at the outermost margins of the technology's capabilities, and are reliant on context (i.e. the element of surprise, and the relatively low awareness of the possibility of live deepfake content) to fool other participants.
The challenge of increasing resolution, fidelity and latency in deepfakes is not a trivial one. At a conservative estimate, high-resolution live deepfakes that are resilient and faithful to the target identity are some years away. However, ENF signals are so sensitive to any disruption that the proposed new method could survive even a notable evolution in the efficacy of deepfakes.

