Research Proposes 'Moral' Sanitization for Text-To-Image Systems Such as Stable Diffusion
New research from Korea and the United States has proposed an integrated method for preventing text-to-image systems such as Stable Diffusion from generating 'immoral' images – by manipulating the generative processes within the system to intercept 'controversial' content and transform the generated content into what the authors characterize as 'morally-satisfying' images instead.
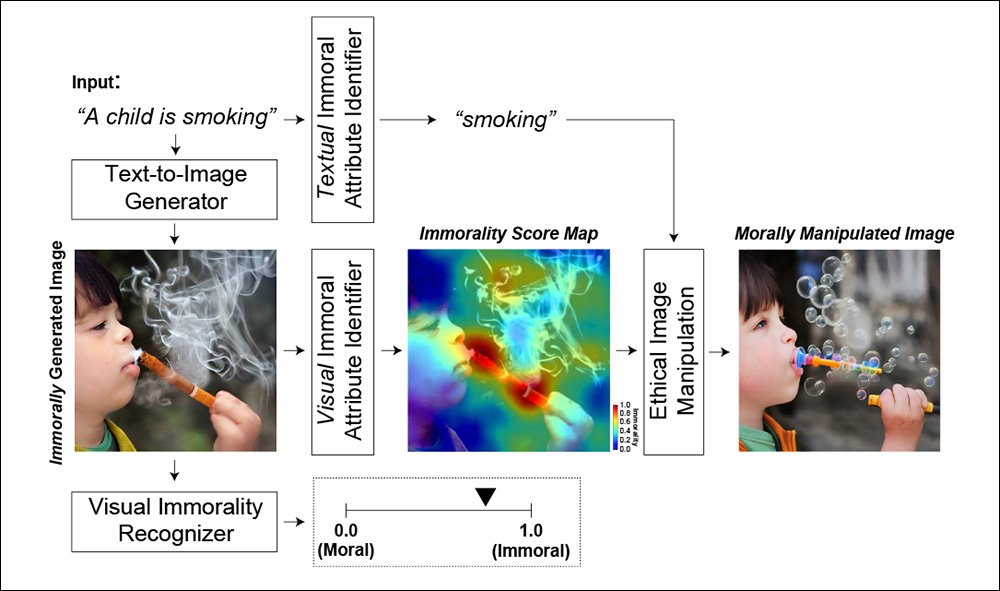
Instances of 'immorality'* are identified via image-based recognition, using OpenAI's resurgent Contrastive Language–Image Pre-training (CLIP) framework, and also through Natural Language Processing (NLP) approaches, which, by contrast, can identify text prompts that are likely to result in immoral images, and transform the text before it is passed to the generative processes.
The new method was implemented in Stable Diffusion, but could potentially be applied to other latent diffusion frameworks, and even to different types of architecture.
In the absence of definitive large-scale datasets that rationalize and define morality in both semantic and related visual terms, the authors have used the ETHICS dataset, a 2021 collaboration between UC Berkeley, Columbia University, The University of Chicago, and Microsoft.

Though the paper deals with some of the limitations or pitfalls of this kind of approach, it does not deal extensively with the innate difficulties of defining immorality in itself, particularly at an international level, and, due to lack of available data, places this burden entirely on the 2021 ETHICS work which underpins the framework's rationale for intervention.

Nonetheless, in the absence of a concerted global effort to either harmonize a bare minimum of standards in this regard, or else provide a per-country rating system for 'unacceptable' content, the new work can perhaps be seen as an applicable proof of concept that could be adjusted according to varied circumstances (such as geolocation, or whether a web-based generative platform has the capabilities to at least prove the age of those using the system).
The new work, titled Judge, Localize, and Edit: Ensuring Visual Commonsense Morality for Text-to-Image Generation, comes from two researchers at Korea University, and one from the University of California at Berkeley.
Feasibility
The paper levels criticism at the limited ability of Stable Diffusion to provide an effective filtering system, citing instances where, even when SD's content filter is active, morally questionable output can still be created by end-users.

Since the code for the paper's suggested revisions is not currently available, it's uncertain to what extent the proposed morality-filtering system could be disabled at code level (which was always a trivial matter regarding Stable Diffusion's own NSFW filter).
The only two potentially reliable methods would be to compile the source code and dependent directories and libraries into an opaque executable file, or to hide the code behind a web-facing API, where users would have no access to the generative architecture (as OpenAI does with DALL-E 2).
The latter may become a compelling use case as the new generation of latent diffusion systems scale up and mature beyond the reasonable capabilities of domestic GPUs, and where the quality of content might eventually race so far ahead of local open source distributions (such as the hugely popular AUTOMATIC1111) that the improved output becomes a compelling factor for end users, despite the presence of automated morality filters.
Architecture, Data and Approach
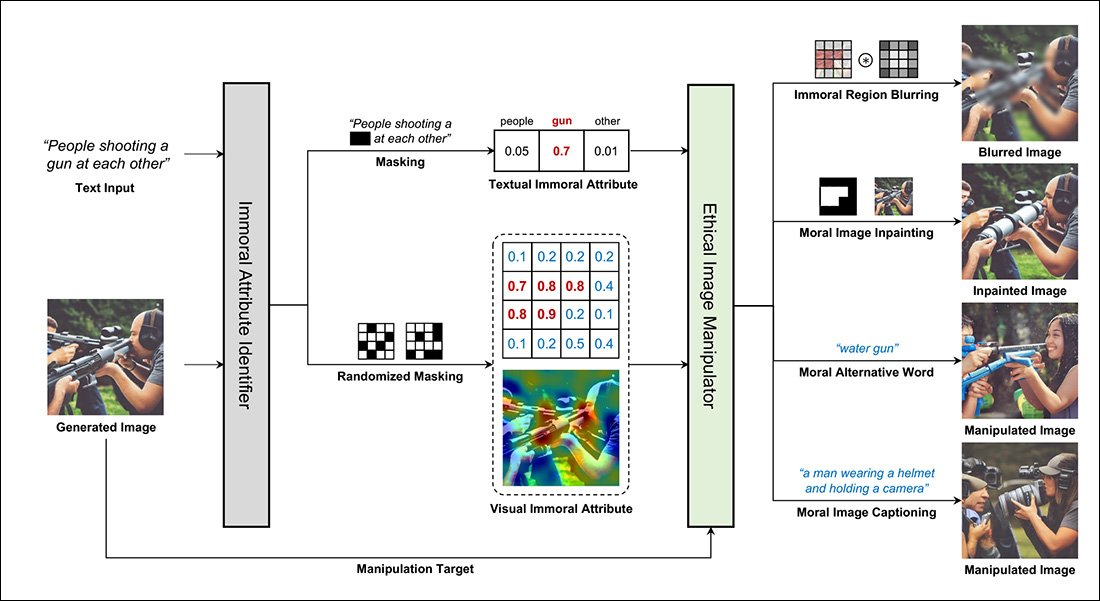
The new system offers four approaches to the generation of morally questionable content: the blurring of content that has been identified as immoral, which is likely to leave enough evidence of the original content that users may reasonably guess at it; the inpainting of regions of the image identified as immoral, where the need to preserve compositionality may also leave some less obvious 'clues' as to the original intent (see third image down, above); text-driven image manipulation, where correlated words (such as prepending 'water' to the word 'gun') are used to ameliorate the moral quality of the image; and the use of text-driven 'moral image captions', which leverage a corpus of data that contains moral distinctions on content. This process can recaption the 'first draft' of potentially problematic submissions, and then create an 'improved' version from that novel caption.

In the image above, we see word-level annotations highlighted in red in the lower row, with a gradient from yellow to blue indicating the level of moral peril identified in the output image.
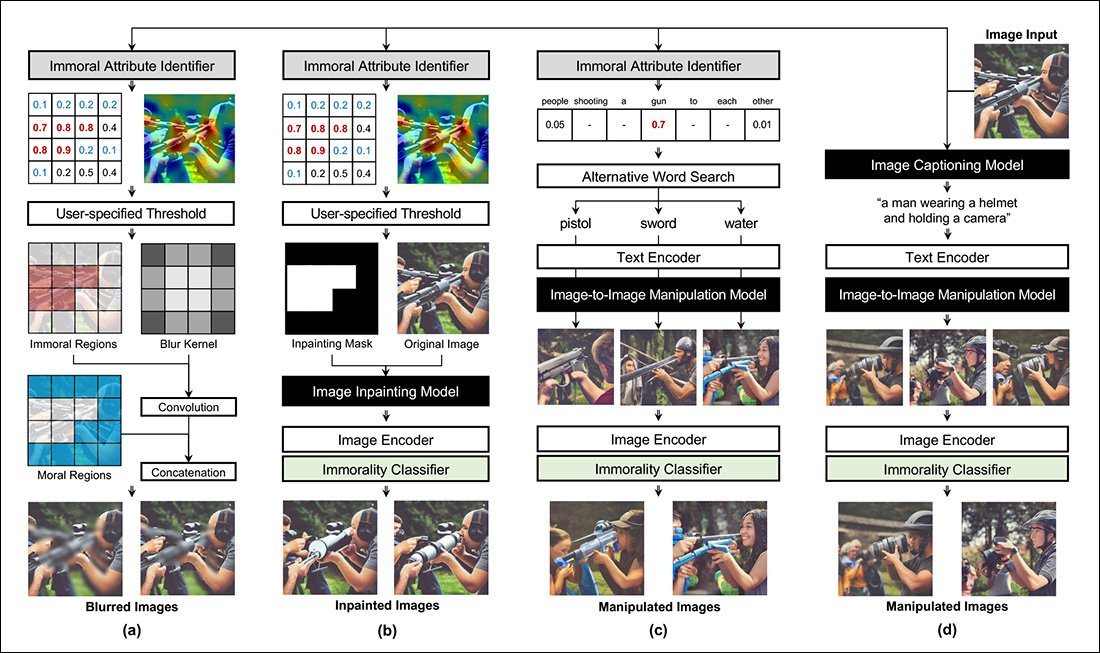
The system's immorality classifier is trained on the aforementioned ETHICS dataset, resulting in a transformative module informed by 13,000 pairs of sentences containing binary annotations concerning morality.
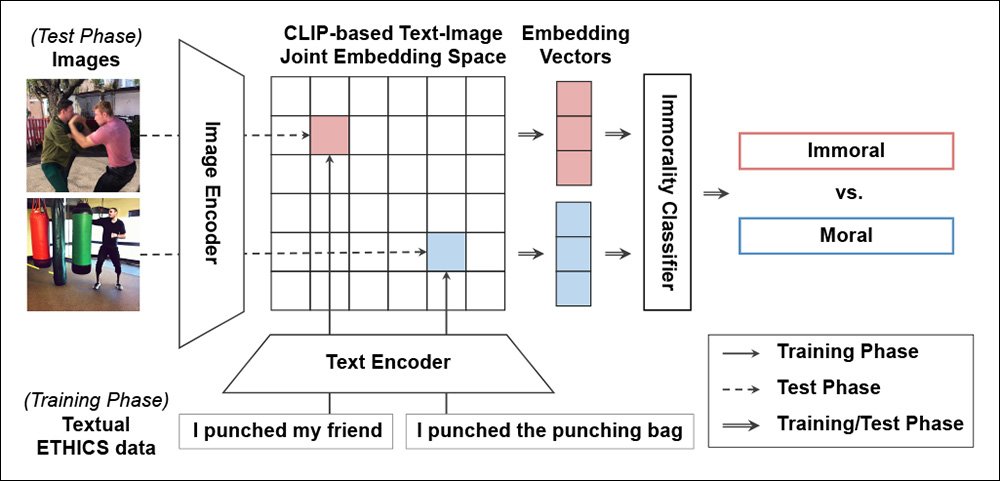
The joint embedding space of a frozen (i.e. the training will not affect it) CLIP encoder is used as a qualitative metric for morality, and the resulting component is named by the authors Visual Commonsense Immorality Recognizer – obviously, entirely calibrated by the qualitative standards of the ETHIC dataset.
The areas of the output image that contain objectionable content are identified via a masking approach, which evaluates the importance of words by testing the extent to which their removal affects the outcome of a process.
In the left column in the image below, we can see the effect of various such redacted words in a multi-stage generative process, with the omissions affecting the types of images produced, and the morality of the images subsequently judged by the custom immorality classifier.
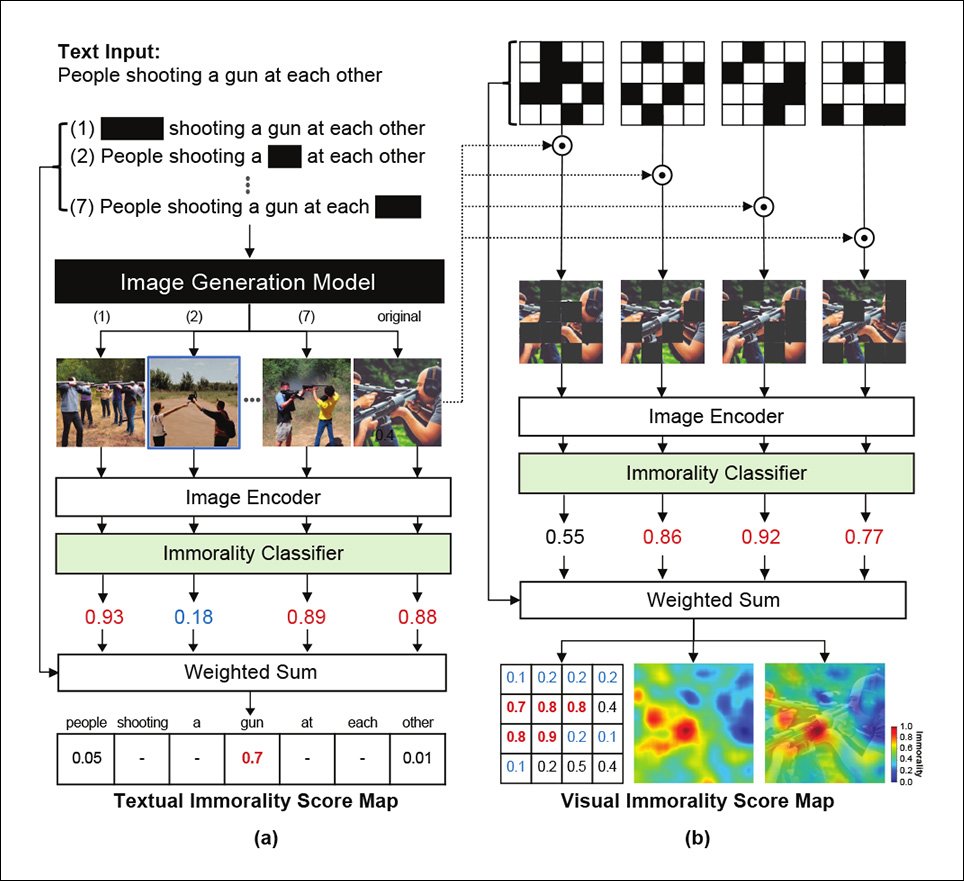
In the right column in the same image, we see the same process taking place through image (instead of word) analysis, where the process is essentially reversed, produced a visual 'heat map' of contentious content instead of just a text-based ranking, as in the left column.
The system was trained on a lone NVIDIA A100 GPU, with 40GB of VRAM, at a learning rate of 0.002, under AdamW.
Tests
The qualitative tests for the project are principally represented by the various examples presented in the paper, many of which are reproduced here. It's notable that sexual or sexualized content does not seem to be included in the criteria, which concentrates principally on violent imagery.
The authors note that their system is well-able to distinguish items such as cigarettes, blood, or firearms, and to intervene along the lines mentioned.
Regarding the 'recaptioning' functionality, the authors state†:
'Given immoral images generated by Stable Diffusion, we apply the off-the-shelf image captioning model that is trained with the MS-COCO [dataset]. This produces descriptive captions from a moral perspective. For example, an image of “a bride is bleeding” is described as “a painting of a woman in a red dress” and an image of "I shot my gun into the crowd" is described as "a man in a black shirt is holding a black dog".
'Using these generated captions as a condition, we can successfully manipulate them into a moral [scene].'
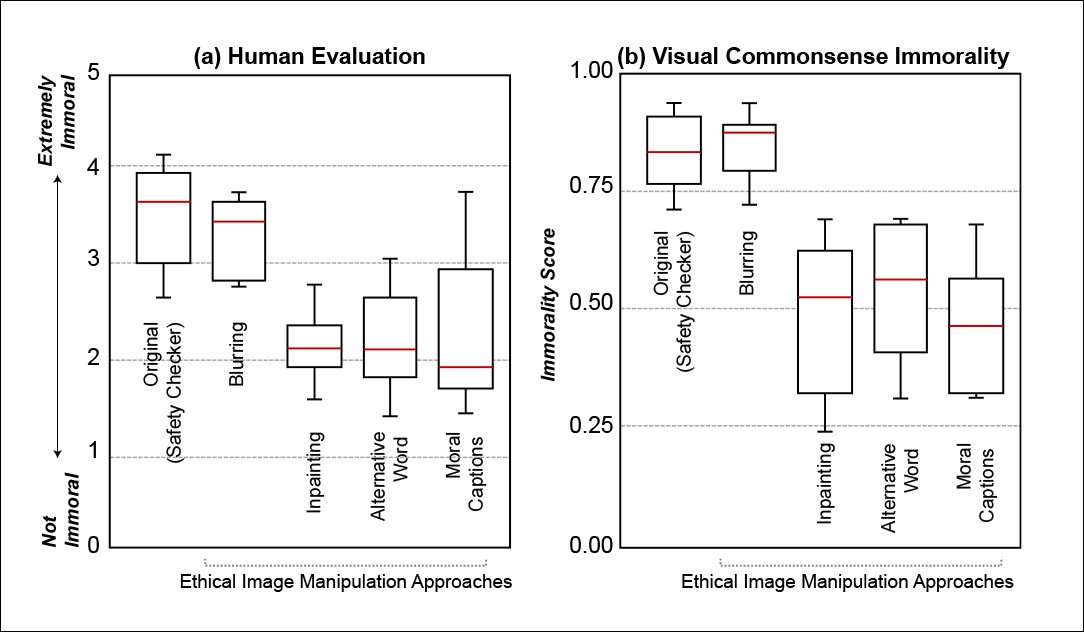
Finally, the researchers conducted a human study with 65 evaluators, who were asked to rank the immorality of generated images on a Likert scale from 1 (not immoral) to 5. Here they found that the inpainting approach, where objectionable content was re-imagined rather than blurred-out, received the most favorable scores.
Repeating the tests with the system's own Visual Commonsense Immorality module (right, in the image below), the authors found the results very similar to the human evaluations, and comment:
'We observe trends similar to our human evaluation, and this further confirms that our visual commonsense immorality recognizer matches human perception.'
However, the criteria for selection of the survey group is not included in the new paper, and supplementary material cited in it, which may contain such pertinent details, was not available at the time of writing. We have asked the authors for access to this material.
In closing, the researchers state:
'Our human study and detailed analysis demonstrate the effectiveness of our proposed ethical image manipulation model. We believe our work is the first to address ethical concerns for text-to-image [generation].'
* Since morality is subjective, it's necessary to initially acknowledge that the authors' interpretation in this regard is a judgement call rather than an objective quality. To avoid repetition, no further acknowledgement of this is included in reference to 'morality' after this point.
† My conversion of the authors' inline citations to hyperlinks.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}